ENACT: Evaluating Embodied Cognition with World Modeling of Egocentric Interaction
ENACT evaluates embodied cognition through egocentric interaction world modeling. Notably, it has a simple and scalable dataset pipeline design.
Dataset Viewer
Explore the ENACT dataset for embodied world modeling tasks.
Loading dataset...
Leaderboard
Performance comparison of different models on our embodied cognition benchmark. Dark highlighting indicates the best result within each category, light highlighting denotes the second-best.
Click on column headers to sort the results
| Model ↕ | Forward World Modeling | Inverse World Modeling | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3↕ | 4↕ | 5↕ | 6↕ | 7↕ | 8↕ | 9↕ | 10↕ | 3↕ | 4↕ | 5↕ | 6↕ | 7↕ | 8↕ | 9↕ | 10↕ | |
Key Findings
Our research reveals critical insights about VLM spatial reasoning capabilities through comprehensive forward and inverse world modeling tasks.
Findings from Forward/Inverse World Modeling Tasks
Key Takeaways
- Higher performance on the inverse task than the forward one highlights stronger language-based retrospection than action-conditioned visual reasoning.
- Long-horizon degradation reveals limited interactive, spatial memory under partial observability.
- The human–model gap shows that current VLMs are still far from robust embodied world models in mobile manipulation settings.
Findings from Probing Tasks
Key Takeaways
- Insensitivity to rendering variations indicates bottlenecks in multi-step interaction reasoning rather than low-level image realism.
- Performance degradation on non-standard views implies VLMs are biased towards human-like egocentric viewpoints and intrinsics.
- Reliance on human-centric visual priors limits generalization to diverse robotic embodiments with non-standard optics.
- VLMs are robust to the embodiment appearance variations.
- VLMs exhibit strong right-handed bias, which is consistent with human handedness distribution.
Performance Analysis
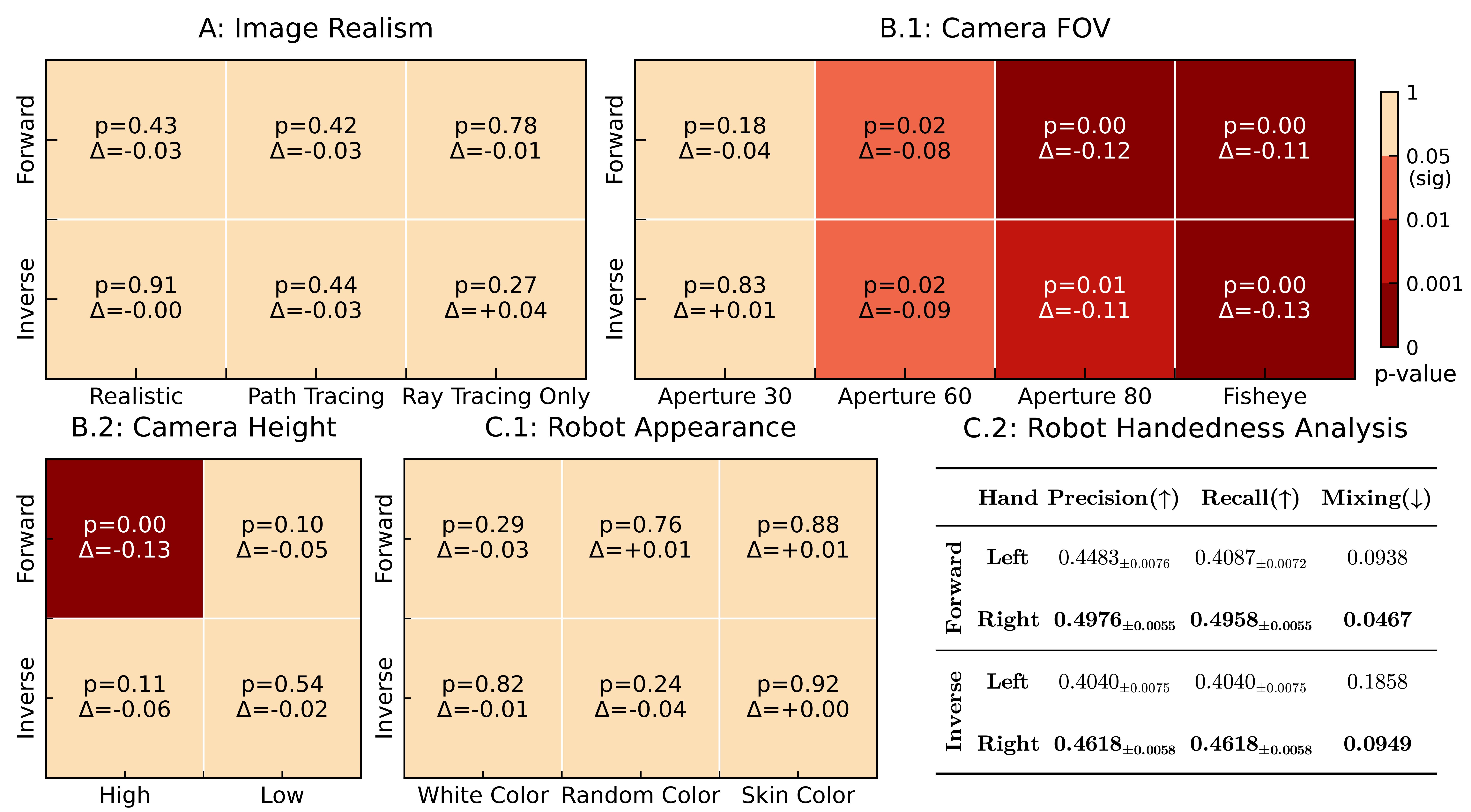
Probing experiment results with GPT-5 mini on ENACT. Heatmaps show two-tailed unpaired t-test results against the baseline, using Pairwise Accuracy. \(p<0.05\) is considered significant. Darker red means more significant. \(\Delta\) is the performance change from the baseline. If significant and \(\Delta<0\), the setting is worse than the baseline. C.2 reports the robot's performance on the left- and right-hand predicates, where Mixing is the proportion of ground truth left or right cases that are predicted as the other hand (i.e., mixing one hand into the other). \(\pm\) means standard error.
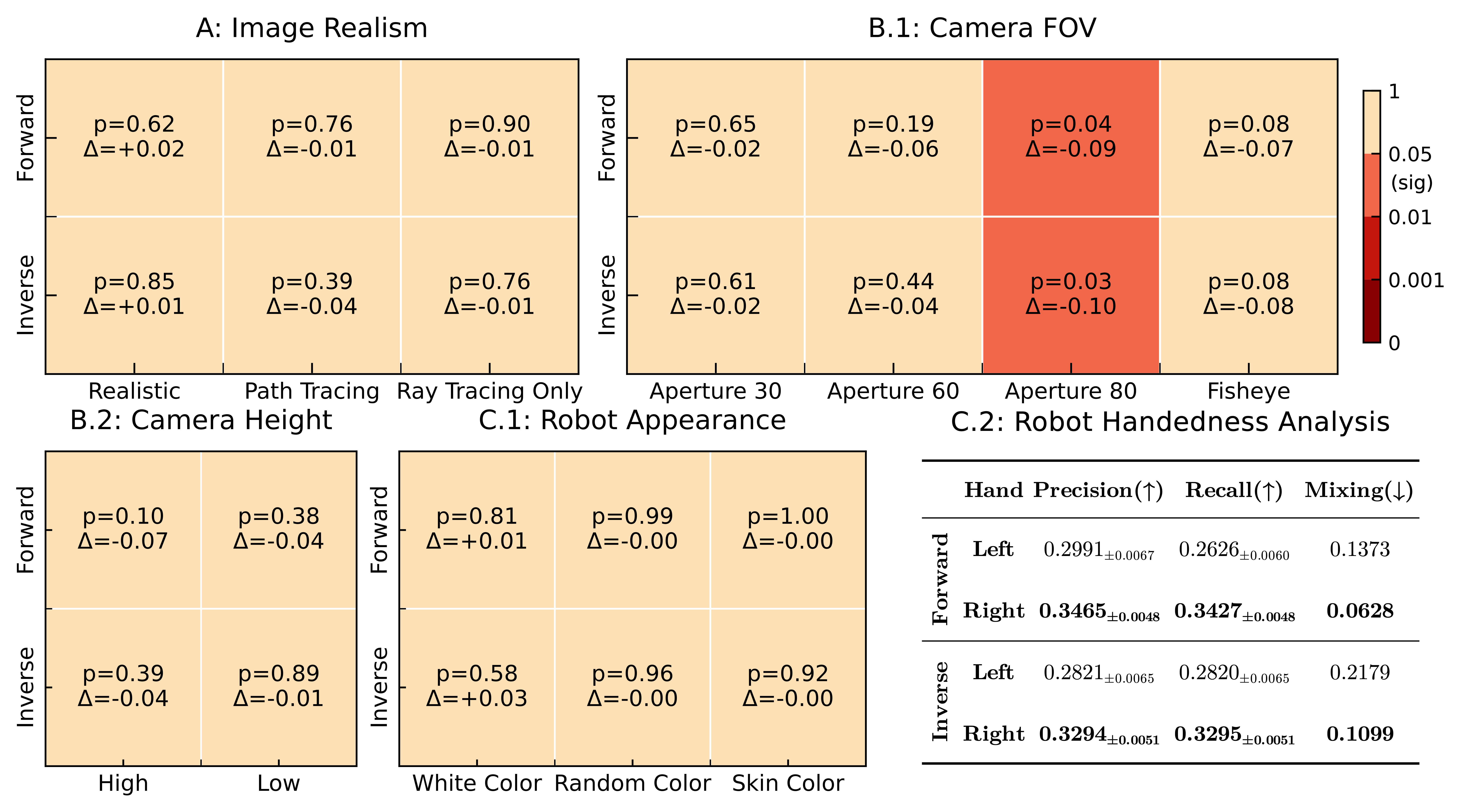
Probing experiment results with InternVL3.5-241B-A28B on ENACT. Heatmaps show two-tailed unpaired p-values against the baseline, using Pairwise Accuracy. \(p<0.05\) is considered significant. Darker red means more significant. \(\Delta\) is the performance change from the baseline. If significant and \(\Delta<0\), the setting is worse than the baseline. C.2 reports the robot's performance on the left- and right-hand predicates, where Mixing is the proportion of ground truth left or right cases that are predicted as the other hand (i.e., mixing one hand into the other hand). Note that, although InternVL3.5-241B-A28B performance is less significant than GPT-5 mini, the \(|\Delta|\) across unnatural camera configurations still remains high (\(>0.05\)) when the same settings are significant for GPT-5 mini.
Image Realism
Key Takeaways
- Insensitivity to rendering variations indicates bottlenecks in multi-step interaction reasoning rather than low-level image realism.





Anthropocentric Bias on Human Vision
Key Takeaways
- Performance degradation on non-standard views implies VLMs are biased towards human-like egocentric viewpoints and intrinsics.
- Reliance on human-centric visual priors limits generalization to diverse robotic embodiments with non-standard optics.
Camera FOV






Camera Height






Anthropocentric bias on Embodiment
Key Takeaways
- VLMs are robust to the embodiment appearance variations.
- VLMs exhibit strong right-handed bias, which is consistent with human handedness distribution.
Robot Appearance






Citation
If you find our work useful in your research, please cite:
@article{wang2025enact,
title={ENACT: Evaluating Embodied Cognition with World Modeling of Egocentric Interaction},
author={Wang, Qineng and Huang, Wenlong and Zhou, Yu and Yin, Hang
and Bao, Tianwei and Lyu, Jianwen and Liu, Weiyu and Zhang, Ruohan
and Wu, Jiajun and Li, Fei-Fei and Li, Manling},
journal={arXiv preprint arXiv:2511.20937},
year={2025}
}